
To make prior art search navigation easier, our tool efficiently separates the wheat from the chaff. To be more specific, during the prior art search, we use reinforcement learning to filter out the noise for relevant judgment.
Traditional Prior Art Search: Time-consuming and Recursive
A prior art search is a recursive process. You start by trying to articulate a technical idea in the form of a query, feeding it to a search engine, waiting for it to give the results, and then going through the results one by one.
As you scroll down the list, the relevance of the results generally decreases. So, you refine your query to get more relevant results, and the process repeats itself.
As you may be aware, only a subset of these results is relevant, with the remainder referred to as “noise.” It is not unusual to see a noise-to-relevance ratio of 50:1 in your results.
It takes the majority of your time to scan hundreds of documents to find one relevant piece of information. Most of your time is spent reading documents that you’re going to eventually discard. As a result, determining the irrelevance of a document as soon as possible is generally advantageous. Regrettably, most search engines place less emphasis on this aspect. They either don’t help you evaluate relevance quickly or only show some highlighted keywords. However, these approaches are rarely sufficient to inform you about the document’s significance.
XLSCOUT, on the other hand, places a strong emphasis on this. We believe that allowing searchers to quickly judge the relevance of documents is one of the most important areas where prior art search engines can improve. Our AI-powered patent search tool employs reinforcement learning to filter the noise from the prior art by displaying the most relevant results at the top of the list.
Let us examine this issue in depth in this article, consider potential solutions, and see how XLSCOUT can assist.
Vague Titles & Irrelevant Text
To keep things simple, let’s assume we’re conducting a prior art search through patent literature. Unfortunately, some patent titles are ambiguous and misleading. For example, the title of one patent was “Method,” and that was it. It is an extreme example, but judging patents based on their titles is difficult in general. Even abstracts are frequently difficult to understand. When conducting a claim or description search, abstracts may not even be directly related to your query.
A typical patent has between 10 and 12 pages of text. However, we frequently come across patents that are longer and contain 50–60 pages of text! When looking for prior art, the information you seek could be found anywhere within the text. Even expert searchers spend 90% of their time looking for that critical piece of information within the text.
Time-efficient Prior Art Search Navigation using XLSCOUT
XLSCOUT put the use of reinforcement learning to its AI-based Novelty Checker (patent searching tool) to get quality patent research reports in just 5 minutes. The Novelty Checker uses reinforcement learning to filter the noise from the prior art by pulling up the relevant results on top of the list. By selecting a few relevant and non-relevant results, users can apply them to the result set. The system takes the user’s feedback and then learns from it. It uses conceptual searching and re-ranks the results by bringing the quality results to the top and sending the noise to the bottom.
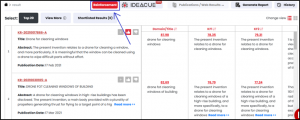
Without reinforcement learning, users go through hundreds of results manually. By applying this process, users can skip going through the non-relevant results. Reinforcement can also be applied multiple times to a result set according to users’ different requirements/criteria. Users can then view the Top-10 or Top-20 results for each criterion to perform a prior-art analysis for idea validation. Users can quickly generate an automated novelty report by selecting these Top-10 or 20 results.

![]()
![]()
![]()
![]()
![]()