データクラスタリングは、特許データの大規模なセットを理解するために不可欠です。また、新しいビジネスを発見し、それらのビジネス分野における競争を理解するのにも役立ちます。「空白」(特許を取得していないように見える領域)を見つけようとしている場合でも、競合他社が取り組んでいる分野や管轄区域を理解しようとしている場合でも、ある技術分野が他の技術分野と比較してどの程度アクティブであるかを理解しようとしている場合でも、プロジェクトの目標を明確に定義し、それらを分類プロセスに適用することが不可欠です。
クラスターの定義:
専門家は、技術分野を詳細に調べ、分析の目的を理解した後、関連する分類法を作成して、結果をより管理しやすく有用なカテゴリに分類する必要があります。分類は、次のことを行う必要があります。
- テクノロジー分野に関連するビジネス関連のすべての質問に回答する
- 潜在的に関連性のある特許文献に開示されている主要な技術の詳細をキャプチャする
- テクノロジー領域の保護が低い領域または空白を特定する
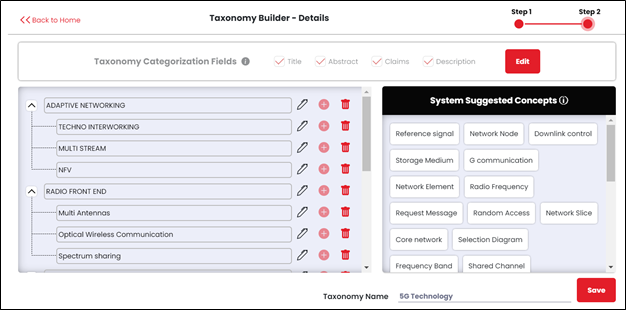
クラスタリングとマッピング:
分類の各クラスター/カテゴリは、タイトル、要約、クレーム、説明などの特許フィールドに基づいて重み付けされます。目的に応じて、ユーザーは1つ以上の特許フィールドを選択できます。通常、上記のフィールドの情報が適切にキャプチャされた場合、特許はクラスタに割り当てられます。
特定のクラスターが重複するため、単一の特許は多くのカテゴリに分割される可能性があります。

洞察 力:
テクノロジー・クラスター (タクソノミ) と他のデータ・ポイント (タクソノミーに基づくポートフォリオ比較、テクノロジー・クラスター・マッピング、クラスターのトレンド分析など) の間のグラフィカルな視覚化は、多数の洞察を生み出す可能性があります。
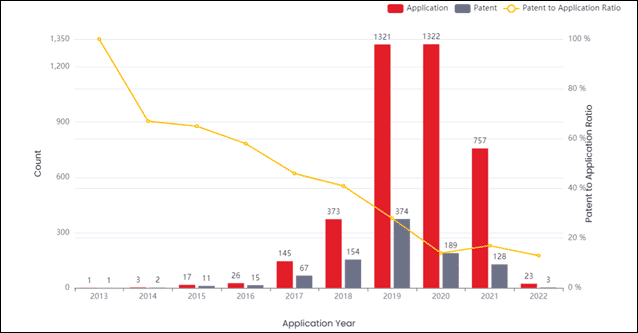
レガシー方法論
特許を技術クラスターに手動で分類するには、各特許を手動で調べます。このプロセスは非常に時間がかかり、複雑です。ほとんどの特許分析ツールは、MLとNLPに基づくクラスタリングエンジンを考案しており、ツールは自動的に特許を技術クラスタに分類します。ただし、クラスタリング エンジンは透過的ではありません。ほとんどのAIベースのクラスタリングエンジンはブラックボックスアプローチに基づいており、ユーザーはこれらのエンジンのバックエンドで何が起こっているのか、エンジンが特許をそれぞれのカテゴリにどのように分類したのか、なぜ分類したのか分かりません。
ニューエイジ方法論
XLSCOUTはガラスボックスアプローチを開発し、特許の分類をユーザーに説明できるようにすることで、特許のランドスケープに説明可能性をもたらしています。説明可能なAIベースの特許分類は、95%の検証済み精度を持っています。この透明性は、この新しい時代のテクノロジーの採用に役立ち、ユーザーに自信を与えると考えています。






