



High-quality clean and standardized data is a prerequisite for a reliable patent landscape analysis. If the data is inaccurate, then the result of the analysis of that data is also going to be inaccurate or unreliable. This inaccurate analysis could lead to incorrect decision-making, costing organizations valuable resources.
Issues with Patent Data
Patent data is notoriously known to be “noisy,” and, for accurate patent landscape analysis, it needs standardization or cleanup. For instance, the Assignee name is one such field that has too much noise. A patent assignee is the name of the entity/organization that has filed for the respective patent application. Inaccuracies in this field could be costly and detrimental to the business. Here are some of the discrepancies in this field:
- Misspellings: These are quite frequent in the assignee field in applications and require correction. For example, Patents belonging to International Business Machine are also filed under Intrnational Business Machine, International Business Machine, etc. To conduct an accurate analysis reflecting IBM’s actual portfolio, standardization of all the misspelled names is necessary since they all represent distinct companies in the databases and would result in incorrect analysis.
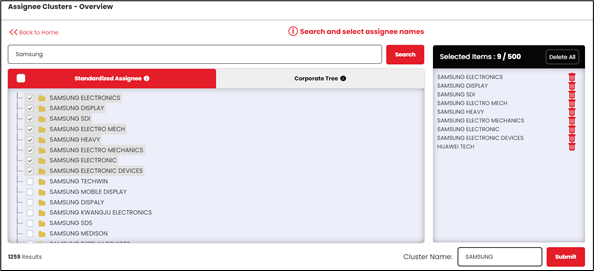
- Name Variations: The assignee field in patents might contain different variations of a single company’s name. For example, IBM alone has around 15+ name variations in this field. IBM, IBM Corporation, and International Business Machine, International Business Machine Corporation are some of the variations of IBM in patents. For an accurate analysis, all variations of IBM need to be combined for searching.
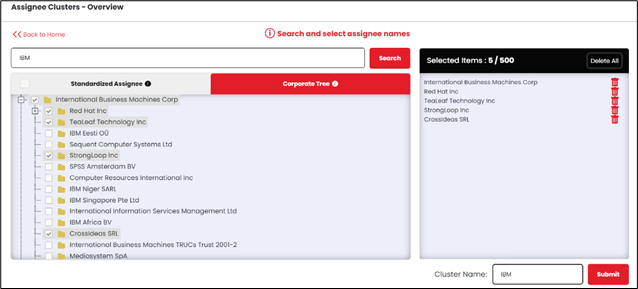
- Corporate Subsidiaries: Most large organizations try to protect their innovations by filing patents through different subsidiaries. However, any analysis of these patents would be inherently incorrect if they were not granted to the parent company that owns the subsidiary. It is necessary to have access to all corporate subsidiaries’ data.
- Translation Errors: Patent Offices make several mistakes while translating original assignee names to their local languages. In most cases, phonetic equivalents of original names are considered while translating. Leaning only on translation tools in such cases might lead to inaccurate analysis.
Why Clean and Standardized data?
Clean and standardized data will aid in a better understanding of the organizations working in a specific field, the size of their total portfolios, the inventors who work for them, and their collaborations or partnerships with other organizations. It is a crucial step to produce statistically relevant/accurate results. Data standardization & cleaning often requires more time than it does to perform the actual analysis, and, if there is a large dataset, it could take many hours if done manually. Using automated tools would assist you in data cleaning and standardization, and in just a few minutes.
Our Methodology
XLSCOUT’s Techscaper, with just a few clicks creates a patent landscape report tailored to your needs. It assists you in resolving data discrepancy woes by offering clean and accurate data. Our data engineering team works diligently to clean and enhance various data points, such as priority data, assignee data, family data, translations, etc., to deliver excellent data quality.
We also provide an ‘Assignee Cluster’ feature which provides users an option to combine various subsidiaries and name variations of a particular company into a single cluster for better analysis.

![]()
![]()
![]()
![]()
![]()