


Abstract
For Explainable AI in R&D, XLSCOUT came up with a unique approach. A corpus of technical concepts is created based on more than 3 billion words and 100GB of pre-processed data. This corpus has been developed on a Machine Learning model.
Background
IP professionals constantly face the challenge of finding related keywords or semantics for a particular technical word. The majority of research documents published worldwide are written using different terminologies based on the country of origin and the subjectivity of the writer. This presents multiple term variations used globally for a single technical word. The swiftly updating technology also introduces new jargon of words that were previously unknown worldwide.
Problem
Online dictionaries as of now, do not cater to the technical terms and are mostly based on routine English words. This makes the job of locating the semantics of technical words a time-consuming and arduous task.
Solution
XLSCOUT-CORPUS solves this global problem and is developed on a data-set comprising of:
- Research Publication Data
- Global Patent Data
- Examiner Datasets
and concurrently train the machine learning model with inputs from researchers from different technological backgrounds like electronics, mechanical engineering, computer sciences, biotechnology, and more.
Technology
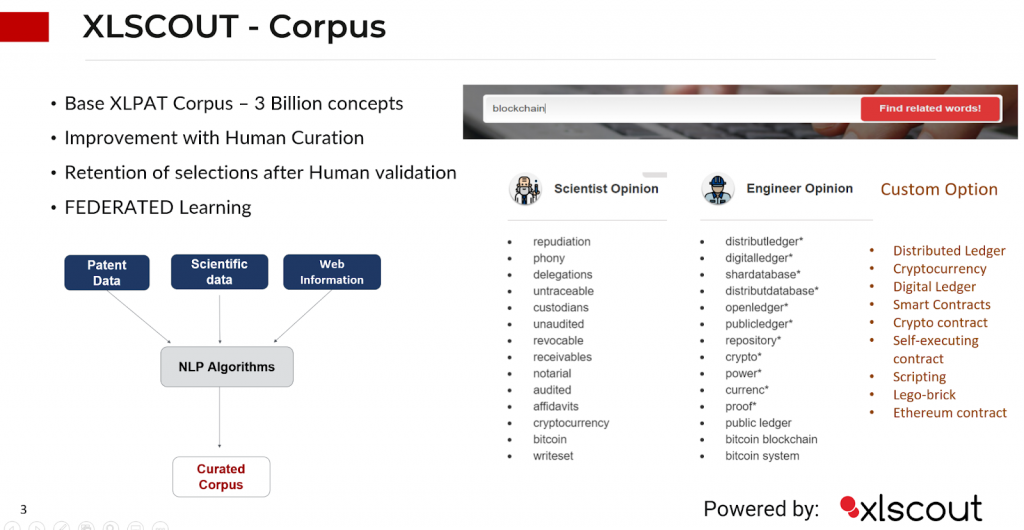
XLSCOUT Corpus is a large lexical database of the technology. Each set of cognitive synonyms, which includes nouns, verbs, adjectives, and adverbs, expresses a different concept. Conceptual-semantic and lexical links connect cognitive synonyms. The resulting network of meaningfully related words and concepts can be retrieved using the XLSCOUT corpus weblink. The XLSCOUT corpus structure makes it a useful tool for computational linguistics and natural language processing.
XLSCOUT Corpus superficially resembles a thesaurus, in that it groups words together based on their meanings. However, there are a few important distinctions.
First, the XLSCOUT Corpus interlinks not just word forms—strings of letters—but specific senses of words. As a result, there is a semantic separation of words that are in close proximity to one another in the network.
Second, the XLSCOUT Corpus labels the semantic relations among words, whereas the groupings of words in a thesaurus do not follow any explicit pattern other than meaning similarity.
Custom Training Option
XLSCOUT Corpus is trained on bulk technology data (generic technology Data) without any reference to a particular technology. When the system predicts synonyms, it predicts all possible synonyms and relations that customers might find overwhelming.
To make it more focused and precise XLSCOUT Corpus provides an option of custom training the ML models by providing customer interest technology bias. This helps in verticalizing the learning of ML models with respect to specific technologies of interest. In turn, the system gives more focused synonyms with accurate interrelationships. thus leading to explainable AI in R&D.
For Example
Use Cases
Explainable Taxonomy (Corpus Assisted)
Corpus assists in creating comprehensive taxonomy for technology breakdown into clusters.
Explainable Categorization
Rule-based Categorization backed by corpus with a possibility of training on expert validated data.
Context Capturing in Novelty & Invalidation Searches
Better semantic variations capturing to perform better prior art searches.

![]()
![]()
![]()
![]()
![]()