
要約
説明可能なAIのために、XLSCOUTはユニークなアプローチを思いつきました。技術的な概念のコーパスは、30億語以上の単語と100GBの前処理されたデータに基づいて作成されます。このコーパスは、機械学習モデルに基づいて開発されました。
バックグラウンド
IPプロフェッショナルは、特定の専門用語に関連するキーワード/セマンティクスを見つけるという課題に常に直面しています。世界中で出版されている研究文書の大部分は、原産国と作家の主観性に基づいて異なる用語を使用して書かれています。これは、1 つの専門用語に対してグローバルに使用される複数の用語のバリエーションを示しています。急速に更新される技術は、以前は世界的に知られていなかった単語の新しい専門用語も導入します。
問題
現在のところ、オンライン辞書は専門用語に対応しておらず、主に日常的な英語の単語に基づいています。このため、専門用語のセマンティクスを見つける作業は、時間がかかり、困難な作業になります。
解決
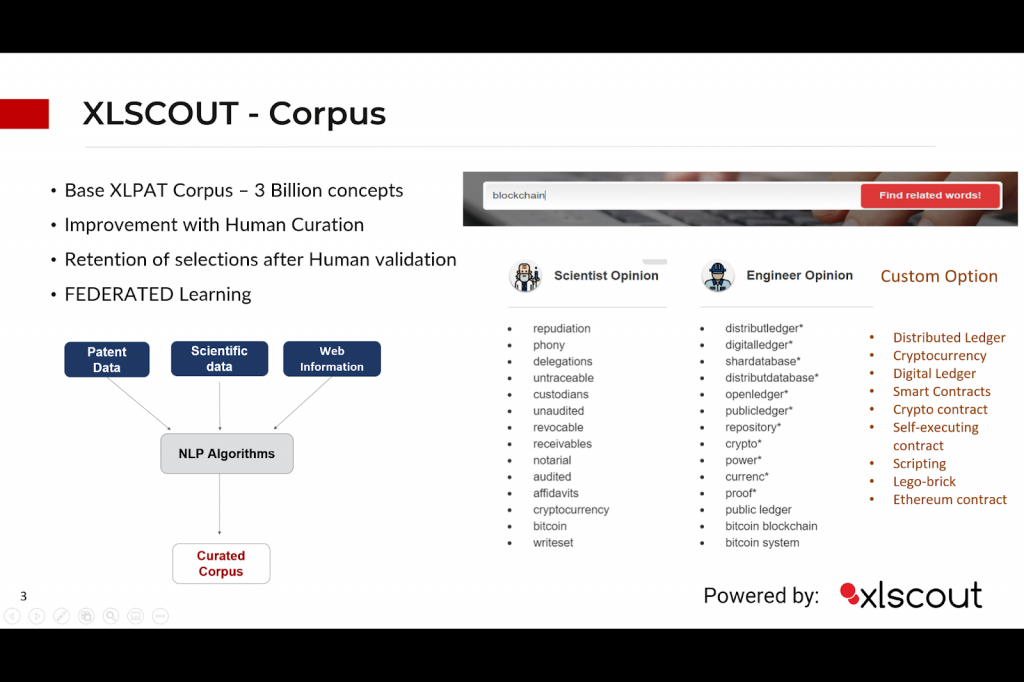
XLSCOUT-CORPUSはこのグローバルな問題を解決し、以下からなるデータセットに基づいて開発されています。
- 研究発表データ
- グローバル特許データ
- 審査官データセット
同時に、エレクトロニクス、機械、コンピュータサイエンス、バイオテクノロジーなどのさまざまな技術的背景からの研究者のインプットと機械学習モデルをトレーニングします。
テクノロジー
XLSCOUTコーパスは、この技術の大規模な語彙データベースです。名詞、動詞、形容詞、副詞を含む認知同義語の各セットは、異なる概念を表現します。概念的セマンティックリンクと語彙的リンクは、認知的同義語を結びつけます。意味のある関連語や概念の結果得られるネットワークは、XLSCOUTコーパスウェブリンクを使用して取得することができます。XLSCOUTコーパス構造は、計算言語学と自然言語処理のための有用なツールになります。
XLSCOUTコーパスは、意味に基づいて単語をグループ化するという点で、表面的にはシソーラスに似ています。ただし、いくつかの重要な違いがあります。
まず、XLSCOUTコーパスは単語の形(文字の文字列)だけでなく、単語の特定の感覚を相互にリンクします。その結果、ネットワーク内で互いに近接している単語の意味的に分離されます。
第二に、XLSCOUTコーパスは単語間の意味関係にラベルを付けますが、シソーラス内の単語のグループ化は、意味の類似性以外の明示的なパターンに従っていません。
カスタムトレーニングオプション
XLSCOUTコーパスは、特定の技術への参照なしに、バルク技術データ(汎用技術データ)で訓練されています。システムがシノニムを予測すると、顧客が圧倒的な情報として見つける可能性のあるすべてのシノニムとリレーションが予測されます。
XLSCOUTコーパスは、より焦点を絞った正確なものにするために、顧客の関心の技術バイアスを提供することにより、MLモデルをカスタムトレーニングするオプションを提供します。これは、関心のある特定のテクノロジに関する ML モデルの学習を垂直化するのに役立ちます。次に、システムは正確な相互関係とより焦点を絞った同義語を提供します。したがって、R&Dにおける説明可能なAIにつながります。
例えば
使用例
説明可能な分類法 (コーパス支援)
コーパスは、クラスターへのテクノロジの分解のための包括的な分類法の作成を支援します。
説明可能な分類
コーパスに裏打ちされたルールベースの分類と、専門家が検証したデータに関するトレーニングの可能性。
ノベルティ検索と無効化検索でのコンテキストキャプチャ
より良い先行技術検索を実行するために、より良いセマンティックバリエーションをキャプチャします。





